Methods for Approximating Page Number
Page approximation will be the center piece of the project moving forward, so accuracy is paramount.
Progress Method
The earliest versions of the program were based on the progress method. This simple method finds the index of a phrase’s first occurence within a text and uses it to approximate a page number. The index is then divided by the total length of the string and multiplied by the total number of pages within the text. The result is an approximate page number, found through use of ratios.
Polynomial Method
Analysis of the former method was proof enough that significant improvements could be made. This led to inspiration for the Polynomial method, which uses manually- gathered data to generate a best-fit polynomial curve. Data collection involves recording the first twenty characters from an arbitrary number of (evenly-spaced) pages. These phrase-page pairings are stored in a text file and read during execution, where they are converted to index-page pairings. Using Python’s polyfit module, a best-fit curve is generated. This curve is then used to approximate pages numbers, given the index of the desired phrase.
Least-Squares and Graphical Comparisons
My first base of comparison involved using the least-squares method for testing goodness of fit. More than anything, this test highlighted issues with the progress method. While the polynomial method had a least-squares value of 8.35, the progress method weighed in at 99.01 (quite awful).
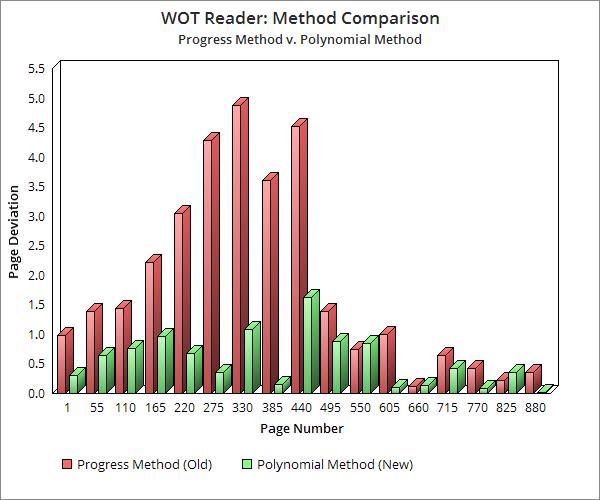
As evidenced by the above graph, the polynomial method provides much more dependable figures than the progress method. Deviation for the polynomial method does not, at any point, exceed two pages (max 0.227% error for 880 pages). This is quite ideal, considering the average length of these novels.
Drawbacks to Consider
Moving forward, I can almost guarantee I will be sticking with the polynomial method for approximating page numbers. That said, I very much recognize that this implementation requires more work on the users behalf in order to ensure system accuracy. This is not necessarily what I had in mind for the project but, being that books take longer than a few hours to read, I believe the initial investment will still save time.