Limiting Scope for the Audiobook Project
The direction for the side project has slowly changed over time. The first component uses VLC and mp3 data to track reader position, whereas the new component uses converted epub data.
Limiting Scope
There are several issues with assuming data gathered for this project can be globally applicable. I will continue testing the program using only the Wheel of Time series, written by Robert Jordan (and Brandon Sanderson). The series is a solid fit, as there are more than 10 books, all printed by the same publishing company.
Ultimately, I want to track reader position using playback from a narrator. I am still exploring speech-to-text technologies to help with this.. Regardless, I need to be accurate when approximating page numbers using the phrases acquired from speech-to-text. I am testing this aspect of the program manually for now. The x-axis of the graph below represents page numbers within the text, while the y-axis represents deviation for program output. In every case, phrases where pulled from the the first available line on each page.
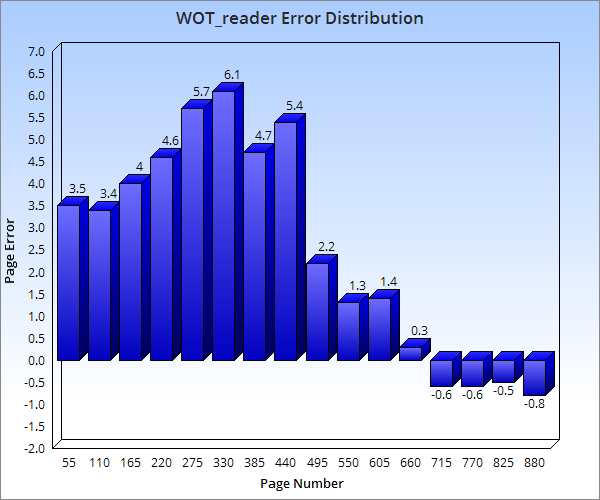
The graph does not suggest much of anything conclusive, but it does lend insight to some of my issues. I can eyeball a seemingly normal distribution, though the mean for this distribution is biased to the left. The bias presumably exists because of “filler” content such as table of contents, about the author, etc.. Epub conversion gathers that text and skews the distribution until about half way through the book.